
The Annotation Scarcity Paradox: Why African AI is Facing an Evaluation Crisis
Happy Africa Day. We are witnessing "language data flaring" in NLP. Here is how we build a sovereign digital future for the continent's 2,000+ languages.

Happy Africa Day! 🌍
As we celebrate our continent’s rich heritage and linguistic diversity this morning, it is a critical moment to ask: Who is building the digital future of our languages, and how are they doing it? Today, we are thrilled to highlight a new preprint from our Principal Investigator, Prof. Vukosi Marivate, titled: “The Annotation Scarcity Paradox in Low-Resource NLP Evaluation.” The paper takes a hard, critical look at the recent history of African AI representation. While the last decade has seen explosive growth in natural language processing (NLP), it’s important to understand how we arrived at our current ecosystem, and why the way we evaluate these AI systems is fundamentally broken.
A Brief History of Extraction
To understand the present, the paper traces NLP’s evolution regarding African languages across two distinct recent eras:
The “Early Boom” (2014–2018): This period was marked by initial optimism. However, the creation of foundational text corpora relied heavily on opportunistic data scraping. Models were built, but they often lacked true sociolinguistic context and domain relevance to the people actually speaking the languages.
The “Scaling Challenge” (2019–2022): Driven by Massively Multilingual Language Models, this era saw a rapid proliferation of shared tasks and benchmarks. The downside? The intense pressure to make languages easily comparable on standardised leaderboards frequently flattened the vital morphological and syntactic distinctions that make African language families unique.
The Annotation Scarcity Paradox
That history brings us to today, where we find ourselves trapped in what the paper defines as the “Annotation Scarcity Paradox.”
We are living in an era of generative AI where the technical capacity to build and scale models has vastly outpaced our human infrastructure. Evaluating the complex outputs of modern AI requires deep linguistic expertise and sovereign community participation, resources that are currently strained, inequitably distributed, and structurally marginalised.
The result is a phenomenon we call “language data flaring.” (Adebara, 2025) Much like the wasteful burning of natural gas during oil extraction, models aggressively harvest what they can, while vast amounts of existing African linguistic resources suffer from systemic neglect. Meanwhile, local communities are relegated to providing undercompensated “ghost work” to align global models.
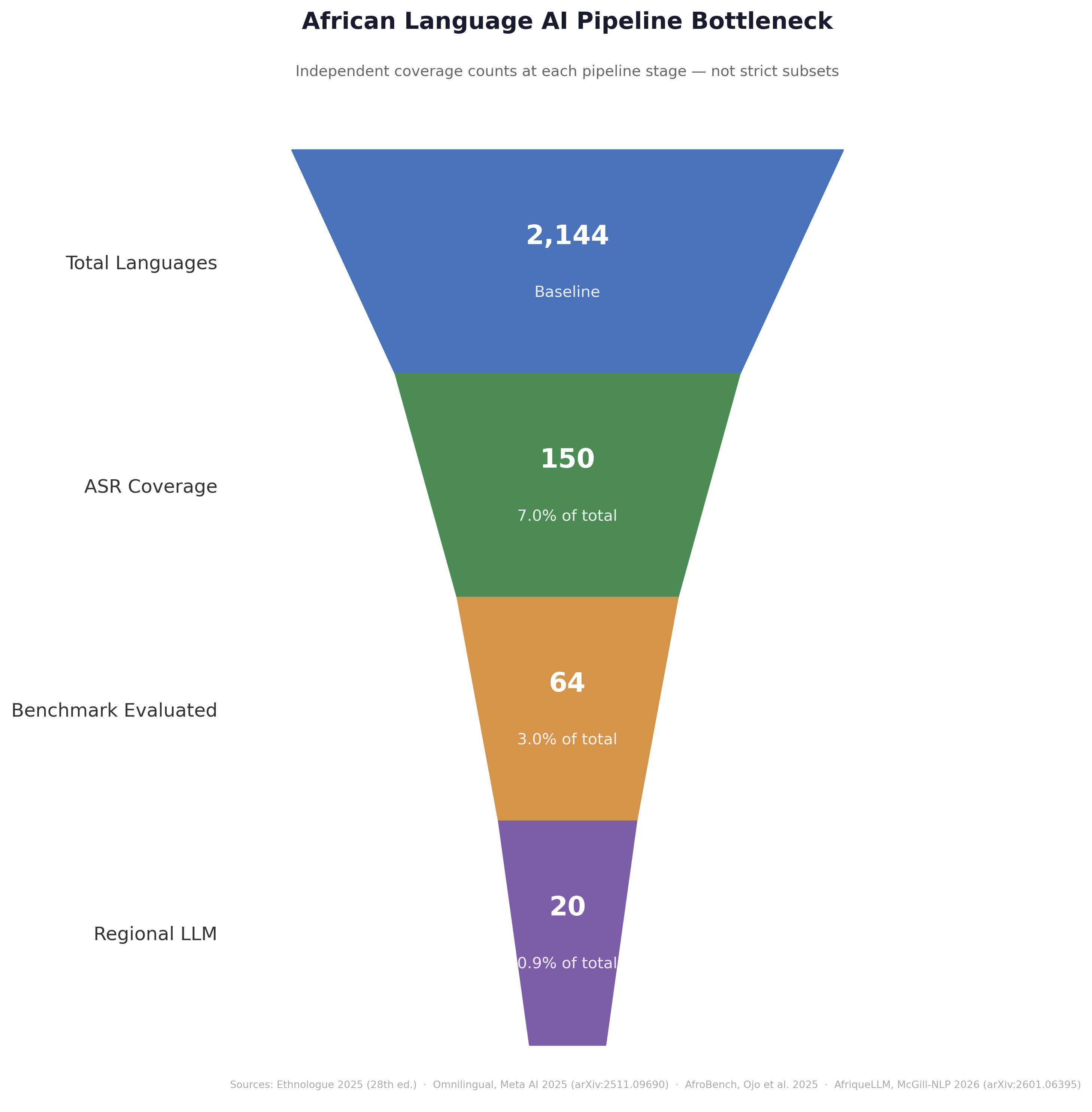
The numbers reveal a stark representation gap. dOut of the 2,144 languages spoken across the African continent:
Only 64 are evaluated in major NLP benchmarks.
A mere 20 are currently served by a regional LLM.
Charting a Sovereign Way Forward
We cannot continue with business as usual. Overcoming this bottleneck requires a multi-faceted approach that addresses both the technical and the structural deficits in our ecosystem.
Technically, we need to implement better, more efficient sample annotation practices and utilise careful data augmentation to maximise the value of the data we already have.
But technical fixes are not enough. We must fundamentally shift our approach from transactional data extraction toward relational, community-embedded evaluation. If we want to build robust AI that genuinely serves African communities, we must root our pipelines in shared ownership. Achieving true data sovereignty means adopting and enforcing equitable licensing frameworks, such as the Nwulite Obodo Open Data License (NOODL) and the Esethu framework, ensuring that the communities providing the knowledge retain control over how it is used.
As we look to the future of AI in Africa, let’s commit to building an ecosystem that doesn’t just extract from our languages, but actively sustains and empowers the people who speak them.
Read the full preprint here: https://arxiv.org/abs/2605.19066